实验3是通过编写wordcount.java进行MapReduce词频统计。原实验是通过安装eclipse插件再通过eclipse运行wordcount.java进行词频统计,不过这个教程比较繁琐同时目前也没有用eclipse,研究了一下IDEA的类似插件发现还是比较麻烦,最后参考了某大佬的wiki直接在Hadoop节点虚拟机上编写打包运行wordcount.java进行词频统计。
实验步骤
开启master和各slave虚拟机并设置环境变量
- 编辑环境变量:
1
vim ~/.bashrc
- 在最后一行添加:
1 2 3 4
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.382.b05-1.el7_9.x86_64 export HADOOP_HOME=/opt/hadoop/hadoop-2.10.2 export PATH=$PATH:/opt/hadoop/hadoop-2.10.2/sbin:/opt/hadoop/hadoop-2.10.2/bin:${JAVA_HOME}/bin export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar - 使环境变量生效:
1
source ~/.bashrc
在master中启动Hadoop
1
start-all.sh
检查hdfs是否正常工作
- 查看监控页面 http://master:50070
检查yarn是否正常工作
- 查看监控页面 http://master: 8088
编译和打包wordcount程序
- 编辑
1
nano WordCount.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
- 编译
1
hadoop com.sun.tools.javac.Main WordCount.java
成功后目录会多出WordCount.class、WordCount$IntSumReducer.class、 WordCount$TokenizerMapper.class三个文件。
坑:
openjdk默认只有JRE,没有tools.jar以及jar命令,因此无法编译和打包,必须安装openjdk-devel版本

- 打包
1
jar cf wc.jar WordCount*.class
成功后产生wc.jar。
准备数据
- 本地准备txt文件并上传到虚拟机中
推荐一个英文电子书下载网站:七彩英语 - 英文电子书下载站 PDF|TXT格式英文原版原著下载 (qcenglish.com)
下载3本TXT格式的电子书并通过Xftp工具上传到虚拟机上
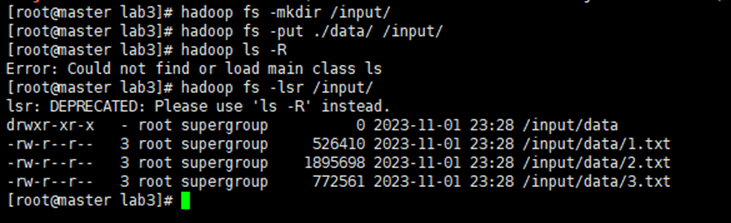
- 把data文件夹传到hadoop集群
在虚拟机内,data所在的目录,执行
1 2
hadoop fs -mkdir /input/ #在hdfs上建立一个/input目录 hadoop fs -put ./data /input/ #把data目录上传到hdfs的/input目录
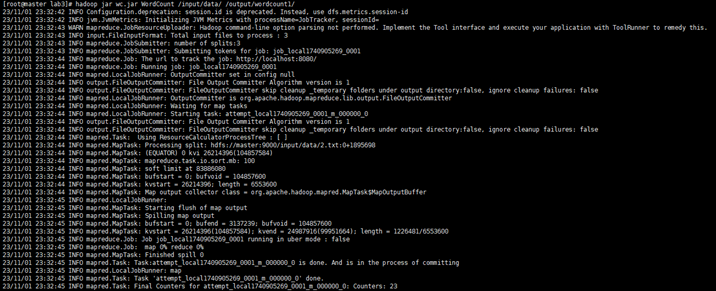
MapReduce,统计词频
- 提交MapReduce任务
在wc.jar所在的目录,运行
1
hadoop jar wc.jar WordCount /input/data/ /output/wordcount1/
- 查看生成的文件
1
hadoop fs -lsr /output/wordcount1

- 查看wordcount输出的内容
1
hadoop fs -cat /output/wordcount1/part-r-00000
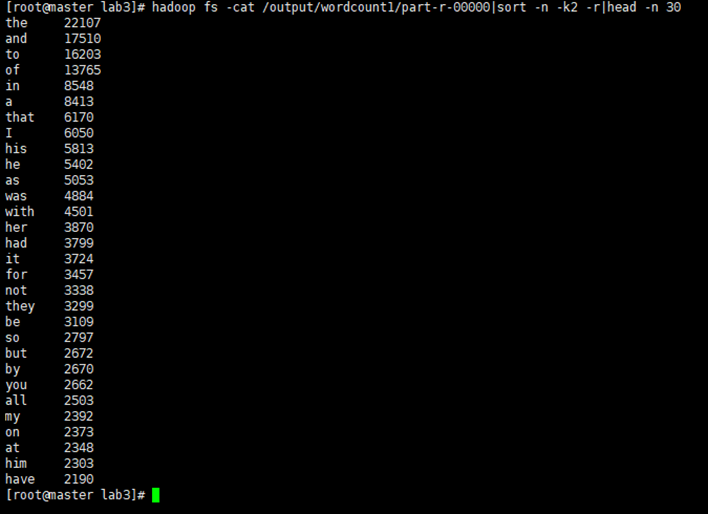
由于字符很多可以输出频率前30的结果
1
hadoop fs -cat /output/wordcount1/part-r-00000|sort -n -k2 -r|head -n 30